Infrastructure & Compute
1. Infrastructure as Competitive Core, Not Support Function
At Turing, infrastructure isn’t a peripheral function. It’s the central competitive advantage for realizing full autonomous driving. End-to-End (E2E) systems require training massive neural networks, continuously evaluating performance, and iterating at scale. As a result, compute resources are not merely tools—they become the resource that determines the speed of technical progress and organizational growth.
For infrastructure investment to justify itself, the question “what will we build on this foundation?” must have a clear answer. At Turing, the priorities are straightforward: increase model development velocity toward full autonomy; increase the throughput of training and validation cycles; ensure developers can fully utilize compute resources without friction. Because these priorities remain fixed, infrastructure decisions stay aligned, and we can move forward while minimizing coordination costs.
2. Current Compute State: The Phase Where Learning Scales Smoothly
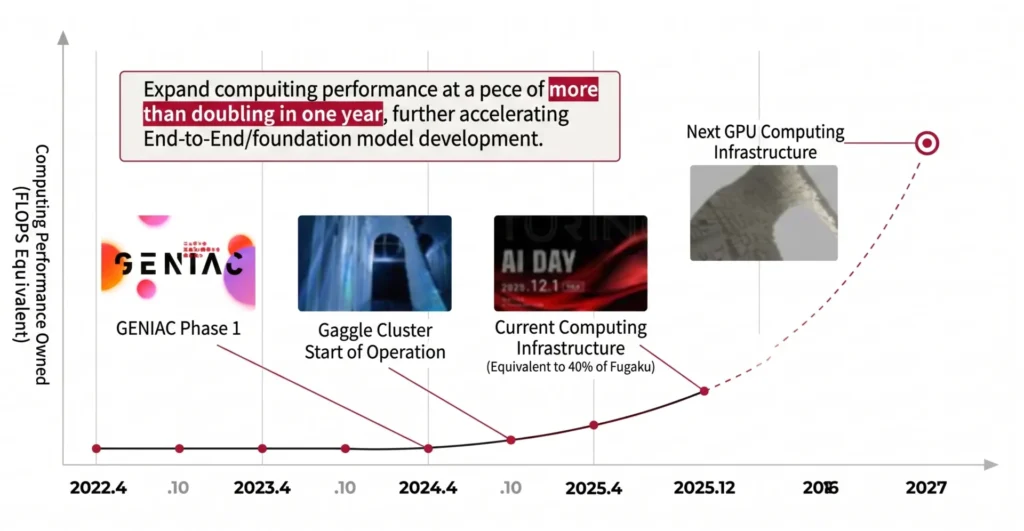
In 2024, Turing completed construction and launched operation of a dedicated AI training cluster. Since then, our compute capacity has grown substantially. As of December 2025, we have approximately 8x the compute capacity of our original infrastructure available on a continuous basis. This scale corresponds to approximately 40% of the Fugaku supercomputer’s AI computing performance (as of November 2025).
Critically, our compute is not sitting idle. Our current autonomous driving models are in a phase where performance scales smoothly with more training data and more compute—we can use every GPU we have. This characteristic makes compute resources even more strategically significant. Insufficient compute slows the improvement cycle; secured compute accelerates it. Infrastructure is directly tied to R&D velocity.
3. AV-Specific Challenges: Data and Storage Dominate
Autonomous driving infrastructure differs fundamentally from typical web service infrastructure. The most important distinction: data is not peripheral—it is central. Images, video, and sensor logs are at the heart of development, accumulating every day. Given the enormous data volumes, storage and I/O are constant bottlenecks.
Training speed isn’t just about GPU performance. What slows training is often not the GPU itself but infrastructure-side constraints: data that can’t be read fast enough, too many files, network congestion. Handling data at millions-of-files scale is an extremely demanding requirement for storage. But since that is how ML engineers naturally work most effectively, it is infrastructure’s responsibility to meet that demand.
In this domain, infrastructure improvements directly translate to outcomes. Shorter compute times mean more experiments per day, which means faster model improvement. This is where infrastructure is visibly an investment, not a cost center—the relationship shows up in numbers.
4. Next-Generation GPU Infrastructure: Designed for 5–10x Scale
We are planning to acquire 5–10x our current compute capacity by December 2027. Specifically, we aim to scale from our current approximately 0.7 exaflops (FP16) to the 3.5–7 exaflop range.
The design philosophy for our next-generation infrastructure is not simply “add more GPUs.” There are three key elements.
First, adopting the latest-generation GPUs to maximize single-server performance. Second, designing around 800Gbps full-bisection networking so that inter-server communication never becomes a bottleneck. Third, building high-speed storage for large-scale video data that supports several GB/s of data access per GPU simultaneously across a cluster of 1,000 GPUs.
This expansion aims to further accelerate End-to-End and foundation model development velocity, extracting maximum AI performance gains.
5. Looking Ahead: Continuously Making Compute Count
The focus going forward is not just adding more compute. We must continuously make compute count—including stable operation of large-scale training, system design that preserves training and evaluation throughput, a developer experience free of friction, and cost-effectiveness optimization.
Full autonomous driving is a long-term competition. Within it, infrastructure remains the precondition that determines the speed at which results are produced. Turing positions infrastructure as a source of competitive advantage, designing across compute resources, networking, storage, and operations together, to further accelerate training and validation cycles.

Join us :
Take on the challenge of fully autonomous driving
with a diverse team of talented members
from various backgrounds.